sudoaptinstallcertbotpython3-certbot-dns-cloudflare-ysudonano/etc/letsencrypt/cloudflare.confdns_cloudflare_email="<email-id>"dns_cloudflare_api_key="<api-key>"# Replace with your Cloudflare API key (Not API Token)sudochmod600/etc/letsencrypt/cloudflare.confsudocertbotcertonly--dns-cloudflare--manual-public-ip-logging-ok-dsample.com-d*.sample.com--manual-auth-hook/etc/letsencrypt/acme-dns-auth.py
sudomysql-uroot-pCREATEDATABASEwordpress;CREATEUSER'wpuser'@'localhost'IDENTIFIEDBY'secure_password'; # Replace with your desired passwordGRANTALLPRIVILEGESONwordpress.*TO'wpuser'@'localhost';FLUSHPRIVILEGES;EXIT;
Download and extract WordPress
cd/var/www/htmlsudowgethttps://wordpress.org/latest.tar.gzsudotar-xvzflatest.tar.gzsudormlatest.tar.gzsudochown-Rwww-data:www-data/var/www/html/wordpresssudochmod-R755/var/www/html/wordpresssudomv/var/www/html/wordpress/wp-config-sample.php/var/www/html/wordpress/wp-config.phpsudonano/var/www/html/wordpress/wp-config.phpdefine('DB_NAME','wordpress' );define('DB_USER','wpuser' );define('DB_PASSWORD','secure_password' ); # Replace with your passworddefine('DB_HOST','localhost' );
Create a new Nginx configuration file for WordPress
JavaScript has evolved significantly over the years, becoming one of the most powerful and versatile programming languages in web development. However, writing efficient, scalable, and maintainable JavaScript code requires mastering advanced techniques. By leveraging modern JavaScript patterns and features, developers can improve execution speed, enhance code modularity, and simplify complex tasks.
This article explores ten essential advanced JavaScript techniques that will elevate your coding skills and help you build robust applications. From closures and destructuring to metaprogramming and memory management, these techniques will give you the edge needed to write professional-level JavaScript.
1. Asynchronous JavaScript with Async/Await
Handling asynchronous tasks effectively is crucial for modern web development. The async/await syntax provides a clean and readable way to manage asynchronous operations, replacing traditional callback-based approaches.
Improves readability by resembling synchronous code.
Simplifies error handling with try/catch.
Reduces deeply nested callback structures.
2. Proxies for Intercepting and Enhancing Object Behavior
JavaScript’s Proxy object allows developers to intercept and modify fundamental operations on objects, making them highly useful for creating custom behaviors such as logging, validation, and dynamic property handling.
Example:
const target = { name:"John" };const handler = {get: (obj, prop) =>`${prop} is ${obj[prop]}`,set: (obj, prop, value) => { console.log(`Setting ${prop} to ${value}`); obj[prop] = value;returntrue; },};const proxy =newProxy(target, handler);console.log(proxy.name); // "name is John"proxy.age =30; // "Setting age to 30"
Why Use Proxies?
Validation: Ensure properties meet certain criteria before being set.
Logging: Track access and modifications to object properties.
Default Values: Provide fallback values for undefined properties.
By using Proxies, you can add powerful meta-programming capabilities to your JavaScript code, enabling more flexible and dynamic object interactions.
3. Debouncing and Throttling for Performance Optimization
Handling frequent user events like scrolling, resizing, or keypresses can impact performance. Debouncing and throttling help control function execution frequency.
Debouncing: Debouncing delays the execution of a function until a specified time has passed since the last event trigger. This is useful for optimizing performance in cases like search input fields and window resize events.
These techniques improve performance by limiting how often a function runs, which is essential for user input handling and optimizing animations.
4. Using Proxies to Intercept Object Behavior
Proxy objects allow you to intercept and redefine fundamental operations on objects, such as property access, assignment, and function calls. This is useful for validation, logging, or building reactive frameworks.
Provides dynamic control over property access and modification.
Enables data validation, logging, and computed properties.
Useful for creating reactive programming frameworks and API wrappers.
Proxies allow developers to intercept and modify object behavior, making them essential for metaprogramming and advanced JavaScript development.
5. Optional Chaining (?.) for Safe Property Access
Optional chaining (?.) provides a way to access deeply nested object properties without worrying about runtime errors due to undefined or null values.
Example:
const user = { profile: { name:"Alice" } };console.log(user.profile?.name); // 'Alice'console.log(user.address?.city); // undefined (no error)
Why Use It?
Prevents runtime errors from missing properties.
Reduces excessive if statements for property checks.
Especially useful when working with API responses.
6. Offload Heavy Tasks with Web Workers
JavaScript is single-threaded, but Web Workers let you run scripts in background threads. Use them for CPU-heavy tasks like data processing or image manipulation:
Prevents UI freezes by offloading CPU-intensive tasks to background threads.
Enhances application responsiveness and performance.
Ideal for data processing, image manipulation, and real-time computations.
Using Web Workers ensures that heavy computations do not block the main thread, leading to a smoother user experience.
7. Master Memory Management
Memory leaks silently degrade performance. Avoid globals, use WeakMap/WeakSet for caches, and monitor leaks with DevTools:
const cache =newWeakMap(); functioncomputeExpensiveValue(obj) {if (!cache.has(obj)) {const result =/* heavy computation */; cache.set(obj, result); }return cache.get(obj);}
Why Use It?
Prevents memory leaks by allowing garbage collection of unused objects.
Efficient for caching without affecting memory consumption.
Useful for managing private data within objects.
Using WeakMap ensures that cached objects are automatically cleaned up when no longer needed, preventing unnecessary memory usage.
8. Currying Functions for Better Reusability
Currying transforms a function that takes multiple arguments into a series of functions, each taking one argument. This technique makes functions more reusable and allows for partial application.
Enables partial application of functions for better reusability.
Enhances functional programming by making functions more flexible.
Improves readability and simplifies repetitive tasks.
Currying is particularly useful for creating highly reusable utility functions in modern JavaScript applications.
9. Closures for Private State Management
Closures are one of JavaScript’s most powerful features. They allow functions to remember and access variables from their outer scope even after the outer function has finished executing. This makes them particularly useful for encapsulating private state and preventing unintended modifications.
Encapsulation: Keep variables private and inaccessible from the global scope.
Data Integrity: Maintain controlled access to data, preventing unintended modifications.
Memory Efficiency: Create function factories that share behavior but maintain separate state.
Callback Functions: Preserve context in asynchronous operations.
Closures are commonly used in event handlers, factory functions, and callback functions to preserve state efficiently.
10. Destructuring for More Concise and Readable Code
Destructuring simplifies the process of extracting values from arrays and objects, making your code cleaner and more readable. This technique is particularly useful when working with complex data structures or API responses.
Object Destructuring:
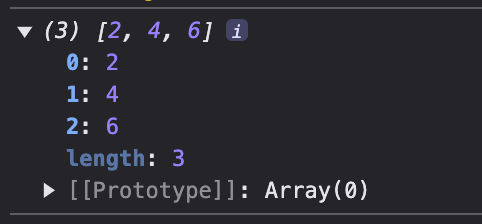
const person = { name:"Jack", age:20 };const { name, age } = person;console.log(name); // 'Jack'console.log(age); // 20
Especially useful when working with API responses or function parameters.
By leveraging destructuring, you can write more concise and expressive code, making it easier to work with complex data structures and improving overall code readability.
Conclusion
By mastering these advanced JavaScript techniques, developers can write cleaner, more efficient, and scalable code. Understanding closures, destructuring, proxies, async/await, and performance optimizations like debouncing and throttling will enhance your ability to build high-performance applications. Additionally, incorporating best practices like the module pattern and optional chaining will further improve your coding efficiency.
JavaScript is a powerful language, but mastering it requires more than just knowing the basics. The real magic lies in the hidden gems — lesser-known but powerful tricks that can make your code cleaner, more efficient, and easier to maintain. Whether you’re a beginner or a seasoned developer, these 10 JavaScript tricks will help you level up your coding game! 👾
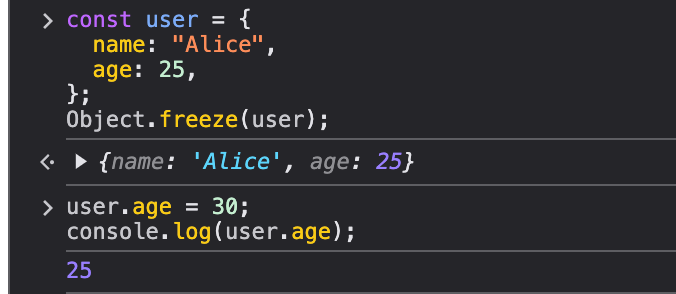
1. Object.freeze() — Making Objects Immutable
In JavaScript, by default objects are mutable, meaning you can change their properties after creation. But what if you need to prevent modifications? That’s where Object.freeze() comes in handy.
const user = { name:"Alice", age:25,};Object.freeze(user);user.age =30; // This won't work, as the object is frozenconsole.log(user.age); // 25
Note: When running the statement user.age = 30; JS won’t throw any error but when we will try to retreve the value of user’s age it will be 25.
Real-World Use Case:
Use Object.freeze() in Redux to ensure state objects remain unchanged, preventing accidental mutations.
2. Destructuring for Cleaner Code
Destructuring makes it easy to extract values from objects and arrays, leading to cleaner and more readable code.
const person = { name:"Bob", age:28, city:"New York" };const { name, age } = person;console.log(name, age); // Bob 28
Real-World Use Case:
Use destructuring in function arguments for cleaner APIs:
functiongreet({ name }) { console.log(`Hello, ${name}!`);}greet(person); // Hello, Bob!
3. Intl API — Effortless Localization
The Intl API provides built-in support for internationalization, allowing you to format dates, numbers, and currencies easily.
Example:
const date =newDate();console.log(new Intl.DateTimeFormat("fr-FR").format(date));
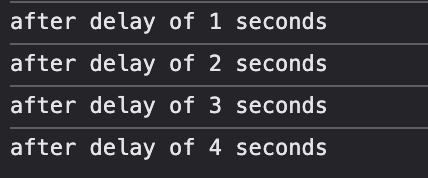
Prevent excessive API calls when a user is typing in a search box.
Final Thoughts
Mastering JavaScript isn’t just about knowing the syntax — it’s about using the right tools and tricks to write better code. These 10 tricks can make your applications faster, cleaner, and more reliable. Try them out and integrate them into your daily coding habits!
One of the most common issues developers face is managing rerenders, especially when working with Context API. Today, I want to share a powerful technique that quite known but… 😄
The Problem with Traditional Context
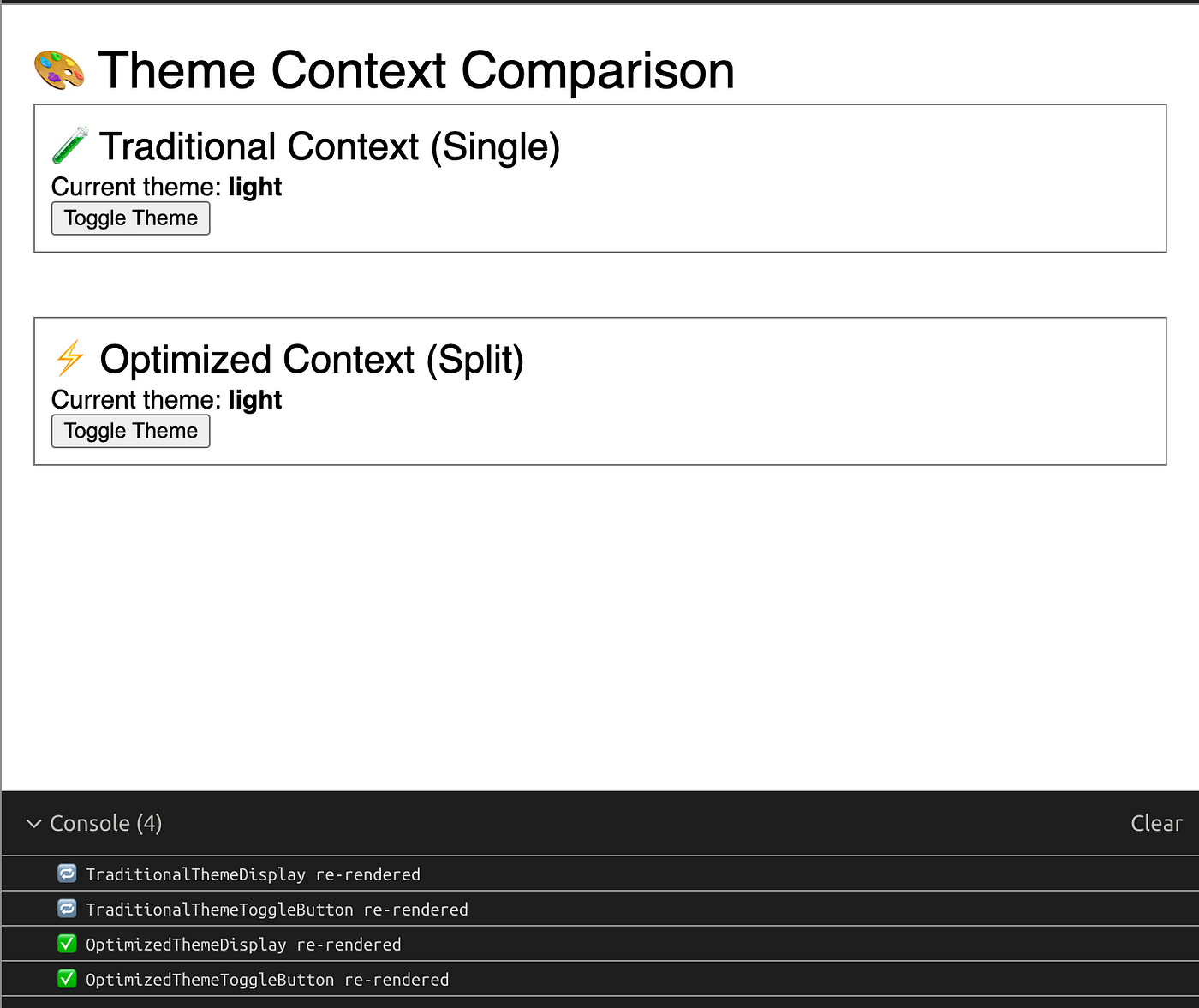
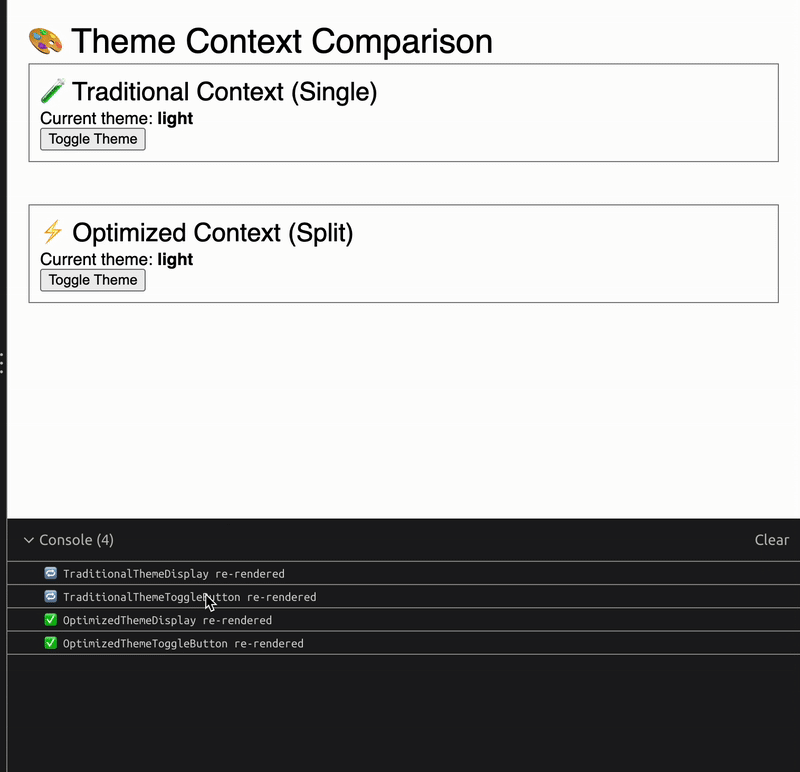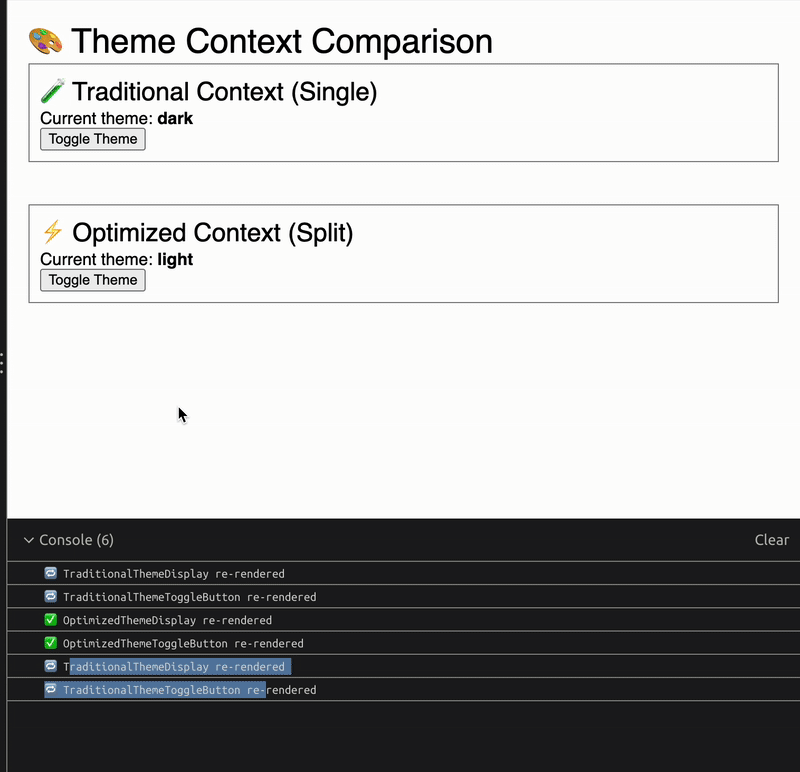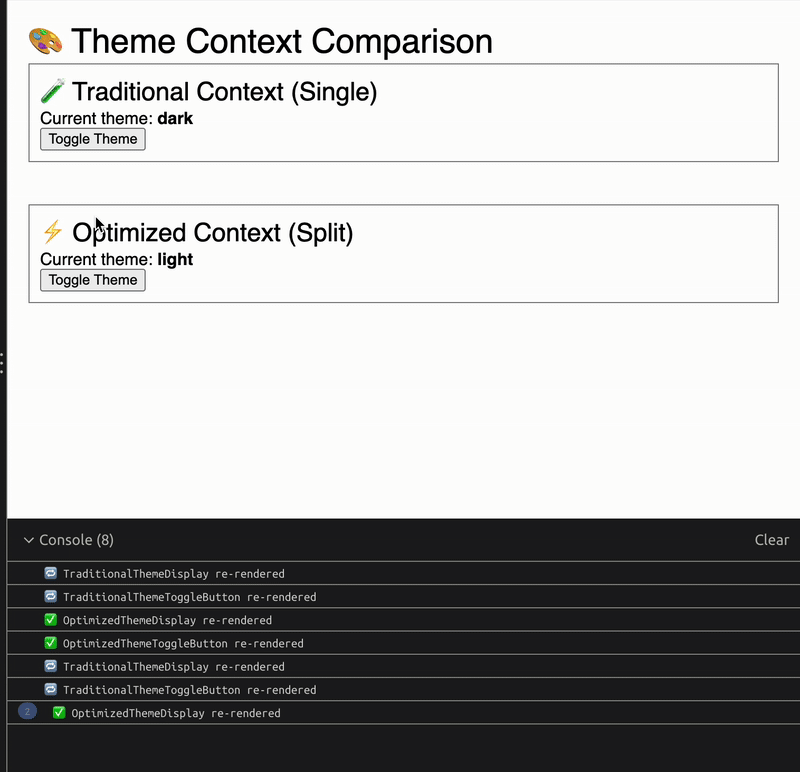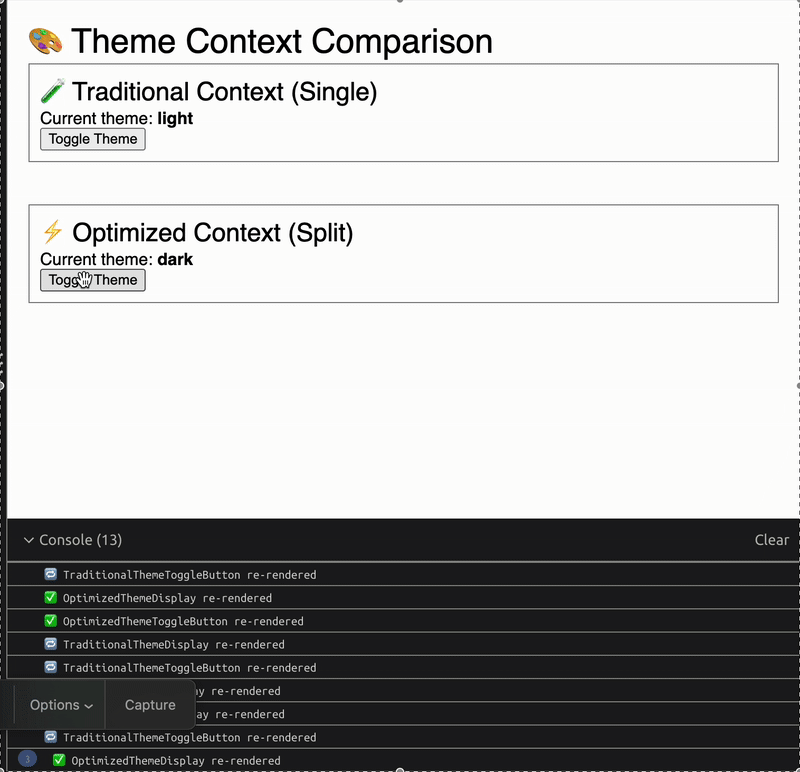
Before diving into the solution, let’s understand the problem. When using React’s Context API in the traditional way, any component that consumes a context will rerender whenever any value within that context changes.
The issue here is that bothThemeDisplay and ThemeToggle will rerender whenever the theme changes, even though ThemeToggle only needs setTheme and doesn’t actually use the current theme value in its rendering.
The Possible Solution: Context Splitting 💡
The context splitting pattern addresses this problem by separating our context into two distinct contexts:
A data context that holds just the state (e.g., theme)
A setter context that holds just the updater function (e.g., setTheme)
ThemeDisplay rerenders (as it should since it displays the theme)
ThemeToggledoes NOT rerender because it only consumes the setter context, which never changes (the setter function reference remains stable)
Complete Example with Rerender Counting 🧪
Let’s create a more complete example that demonstrates the difference between the traditional and split context approaches. We’ll add rerender counters to visualize the performance impact:
✅ OptimizedThemeToggleButton re-rendered ❌ ← does NOT re-render
Optimizing with useMemo
We can optimize the traditional approach somewhat by using useMemo to prevent the context value object from being recreated on every render:
functionOptimizedTraditionalProvider({ children }) {const [theme, setTheme] =useState("light");// Memoize the value object to prevent unnecessary context changesconst value =useMemo( () => ({ theme, setTheme, }), [theme] );return ( <TraditionalThemeContext.Providervalue={value}>{children} </TraditionalThemeContext.Provider> );}
This helps, but still has the fundamental issue that components consuming only setTheme will rerender when theme changes. The split context approach solves this problem more elegantly.
When to Use Context Splitting
Context splitting is particularly valuable when:
You have many components that only need to update state but don’t need to read it
You have expensive components that should only rerender when absolutely necessary
Your app has deep component trees where performance optimization matters
Potential Downsides
While context splitting is powerful, it does come with some trade-offs:
Increased Complexity — Managing two contexts instead of one adds some boilerplate
Provider Nesting — You end up with more nested providers in your component tree
Mental Overhead — Developers need to choose the right context for each use case
Custom Hooks for Clean API
To make this pattern more developer-friendly, you can create custom hooks:
When you run the demo code provided above, you’ll see a clear difference in render counts:
With the traditional context, both the reader and toggler components rerender when the theme changes
With the split context, only the reader rerenders while the toggler’s render count stays the same
This performance difference might seem small in a simple example, but in a real application with dozens or hundreds of components consuming context, the impact can be substantial.
Conclusion 🚀
Context splitting is a powerful technique for optimizing React applications that use the Context API. By separating your state and setter functions into different contexts, you can ensure components only rerender when the specific data they consume changes.
While this technique adds some complexity to your codebase, the performance benefits can be visible in larger applications.
In modern web development, speed and efficiency are important. Whether you’re building with React or using Next.js, caching has become one of the most important techniques for improving performance, reducing server load, and making user experience better.
With the latest updates in Next.js and advancements in the React ecosystem, caching strategies have improved, and learning them is key for any serious developer. In this blog, we’ll learn how caching works in both React and Next.js, go through best practices, and highlight real-world examples that you can apply today.
What is Caching?
Caching refers to the process of storing data temporarily so future requests can be served faster. In the context of web applications, caching can occur at various levels:
Browser caching (storing static assets)
Client-side data caching (with libraries like SWR or React Query)
Server-side caching (Next.js API routes or server actions)
CDN caching (via edge networks)
Effective caching minimizes redundant data fetching, accelerates loading times, and improves the perceived performance of your application.
Caching in React Applications
React doesn’t have built-in caching, but the community provides powerful tools to manage cache effectively on the client side.
1. React Query and SWR for Data Caching
These libraries help cache remote data on the client side and reduce unnecessary requests:
Use cache: 'no-store' for dynamic or user-specific data
2. Using Server Actions and React Server Components (RSC)
// app/actions.ts"use server";exportasyncfunctionsaveData(formData:FormData) {const name = formData.get("name");// Save to database or perform API calls}
Server actions in the App Router allow you to cache server-side logic and fetch results in React Server Components without hydration.
3. Using generateStaticParams and generateMetadata
These methods help Next.js know which routes to pre-build and cache efficiently:
Proper cache invalidation ensures that stale data is replaced with up-to-date content:
Time-based (revalidate: 60 seconds)
On-demand revalidation (res.revalidate in API route)
Tag-based revalidation (coming soon in Next.js)
Mutations trigger refetch in SWR/React Query
CDN and Edge Caching with Next.js
Vercel and other hosting providers like Netlify and Cloudflare deploy Next.js apps globally. Edge caching improves load time by serving users from the nearest region.
Tips:
Leverage Edge Functions for dynamic personalization
Use headers like Cache-Control effectively
Deploy static assets via CDN for better global performance
Final Best Practices
Prefer static rendering where possible
Cache API calls both on server and client
Use persistent cache (IndexedDB/localStorage) when applicable
Memoize expensive computations
Profile and audit cache hits/misses with dev tools
Conclusion
Caching in React and Next.js is no longer optional — it’s essential for delivering fast, resilient, and scalable applications. Whether you’re fetching data client-side or leveraging powerful server-side features in Next.js App Router, the right caching strategy can drastically improve your app’s performance and user satisfaction. As frameworks evolve, staying updated with caching best practices ensures your apps remain performant and competitive.
By applying these techniques, you not only enhance the speed and reliability of your applications but also reduce infrastructure costs and improve SEO outcomes. Start caching smartly today and take your web performance to the next level.
In today’s fast-paced web ecosystem, developers need tools that are flexible, performant, and future-ready. Next.js 15 delivers on all fronts. Whether you’re building static websites, dynamic dashboards, or enterprise-grade applications, this version introduces groundbreaking features that take developer productivity and user experience to the next level.
In this post, we’ll walk through the top 7 features in Next.js 15 that are engineered to supercharge your web apps — plus practical use cases, code examples, and why they matter.
1. 🔄 React Server Actions (Stable with React 19)
Say goodbye to complex API routes. Next.js 15 supports React Server Actions, allowing you to handle server logic directly inside your component files.
🚀 How it works:
// Inside your component file"use server";exportasyncfunctionsaveForm(data) {await db.save(data);}
🧠 Why it matters:
No need to create separate api/ endpoints.
Full type safety with server logic co-located.
Less client-side JavaScript shipped.
Ideal for: Form submissions, database updates, authenticated mutations.
2. 🧭 Stable App Router with Layouts and Nested Routing
Introduced in v13 and now fully stable, the app/ directory in Next.js 15 gives you modular routing with nested layouts, co-located data fetching, and component-based architecture.
Static + Dynamic rendering in one page? Yes, please.
Next.js 15 introduces Partial Prerendering, an experimental feature that allows you to render part of a page statically and the rest dynamically.
💡 Use case:
Your homepage might have:
A statically rendered hero section
A dynamic, user-personalized feed
🧠 Why it matters:
Faster load times for static content
Seamless hydration for dynamic sections
Enhanced user experience without trade-offs
4. ⚡️ Turbopack (Improved Performance)
Turbopack, Vercel’s Rust-based successor to Webpack, continues to mature in Next.js 15. It offers:
Blazing-fast cold starts
Incremental compilation
Near-instant HMR (Hot Module Reloading)
🧪 How to enable:
next dev --turbo
🚀 Why it matters:
10x faster rebuilds compared to Webpack
Smooth DX for teams working on large monorepos
Note: Still experimental but highly promising.
5. 🖼️ Smarter <Image /> Component
Image optimization just got smarter. The updated next/image now supports:
Native lazy loading
Blur-up placeholders
AVIF + WebP support out of the box
🧠 Why it matters:
Faster Core Web Vitals (especially LCP)
Reduced bandwidth and better UX
Simplified image management
6. 🌐 Edge Middleware Enhancements
Next.js 15 improves the DX around Edge Middleware, allowing you to run logic at the edge without cold starts or serverless latency.
📦 Use cases:
A/B Testing
Geolocation-based redirects
Auth checks at the CDN level
🔥 Improvements:
Better logging and error traces
Enhanced compatibility with dynamic routes
7. 🧪 React 19 Compatibility
Next.js 15 is one of the first frameworks fully compatible with React 19, bringing:
React Compiler support (in alpha)
Enhanced Concurrent Features
Better memory and rendering optimizations
🧠 Why it matters:
You can future-proof your app now and explore experimental features with a stable foundation.
Conclusion
Next.js 15 isn’t just about new APIs — it’s about enabling faster, more scalable, and more maintainable apps with less effort. These 7 features are engineered to help modern teams: