Next.js continues to improve with new features that enhance developer experience and performance. One of those features is Server Actions, It’s introduced to simplify server-side logic handling without creating separate API routes. Server Actions helps you to keep your components cleaner, improve security, and provide a better way to handle mutations in both Server and Client Components.
By mastering Server Actions, developers can create fast, reliable, and maintainable full-stack applications with ease.
What Are Server Actions?
Server Actions are asynchronous functions that run only on the server. They are invoked directly from your React components and can handle tasks like database mutations, form processing, and more. These actions simplify server-client interactions by eliminating the need for explicit API endpoints.
To declare a Server Action, use the "use server" directive:
// app/actions/user.ts"use server";exportasyncfunctioncreateUser(formData:FormData) {const name = formData.get("name");const email = formData.get("email");// Save to database herereturn { success:true };}
Using Server Actions in Server Components
In Server Components, you can define Server Actions inline or import them from a separate file. This is especially useful for quick forms or specific mutations tied to one component.
// app/actions/user.ts'use server';exportasyncfunctioncreateUser(formData:FormData) {const name = formData.get('name');const email = formData.get('email');// Save to database herereturn { success:true };}
Using Server Actions in Client Components
You can also use Server Actions in Client Components by importing them from a server-marked module.
// app/actions/user.ts"use server";exportasyncfunctionupdateUser(formData:FormData) {const id = formData.get("id");const name = formData.get("name");// Update user in DBreturn { success:true };}// app/components/EditUserForm.tsx("use client");import { updateUser } from"@/app/actions/user";exportdefaultfunctionEditUserForm() {return ( <formaction={updateUser}> <inputtype="hidden"name="id"value="123" /> <inputtype="text"name="name" /> <buttontype="submit">Update</button> </form> );}
Binding Parameters to Server Actions
You can pass arguments to Server Actions using .bind(), making them dynamic and reusable.
Keep your logic and UI separate. Define Server Actions in dedicated files and import them where needed.
Organize by Domain
Group your actions by feature or domain (actions/user.ts, actions/orders.ts) for better structure.
Error Handling
Use try-catch blocks inside Server Actions to gracefully handle failures and log issues.
Type Safety
Use TypeScript to enforce correct types for FormData fields and return values.
Secure Operations
Always verify user sessions or tokens before making sensitive changes, even inside Server Actions.
Avoid Logic Duplication
Reuse Server Actions across components to prevent writing the same logic multiple times.
Validate Input
Use libraries like Zod or Yup to validate incoming data and avoid corrupting your database.
Final Thoughts
Server Actions offer a powerful pattern for managing server-side logic in a way that feels native to React and Next.js. They simplify the code, reduce the boilerplate of API routes, and make it easier to maintain a full-stack application.
By following the best practices outlined above, you’ll write cleaner, more scalable code that benefits both your team and your users.
The Promise object represents the eventual completion (or failure) of an asynchronous operation and its resulting value.
A Promise is always in one of the following states:
Pending: The initial state, neither fulfilled nor rejected.
Fulfilled: The operation completed successfully.
Rejected: The operation failed.
Unlike “old-style” callbacks, using Promises has the following conventions:
Callback functions will not be called until the current event loop completes.
Even if the asynchronous operation completes (successfully or unsuccessfully), callbacks added via then() afterward will still be called.
You can add multiple callbacks by calling then() multiple times, and they will be executed in the order they were added.
The characteristic feature of Promises is chaining.
Usage
Promise.all([])
When all Promise instances in the array succeed, it returns an array of success results in the order they were requested. If any Promise fails, it enters the failure callback.
const p1 =newPromise((resolve) => {resolve(1);});const p2 =newPromise((resolve) => {resolve(1);});const p3 =Promise.resolve("ok");// If all promises succeed, result will be an array of 3 results.const result =Promise.all([p1, p2, p3]);// If one fails, the result is the failed promise's value.
2. Promise.allSettled([])
The execution will not fail; it returns an array corresponding to the status of each Promise instance in the input array.
If any Promise in the input array fulfills, the returned instance will become fulfilled and return the value of the first fulfilled promise. If all are rejected, it will become rejected.
As soon as any Promise in the array changes state, the state of the race method will change accordingly; the value of the first changed Promise will be passed to the race method’s callback.
Throwing an exception does not change the race state; it is still determined by p1.
Advanced Uses
Here are 9 advanced uses that help developers handle asynchronous operations more efficiently and elegantly.
Concurrency Control
Using Promise.all allows for parallel execution of multiple Promises, but to control the number of simultaneous requests, you can implement a concurrency control function.
9. Using Promises to Implement a Simple Asynchronous Lock
In a multi-threaded environment, you can use Promises to implement a simple asynchronous lock, ensuring that only one task can access shared resources at a time.
This code creates and resolves Promises continuously, implementing a simple FIFO queue to ensure that only one task can access shared resources. The lock variable represents whether there is a task currently executing, always pointing to the Promise of the task in progress. The acquireLock function requests permission to execute and creates a new Promise to wait for the current task to finish.
Conclusion
Promises are an indispensable part of modern JavaScript asynchronous programming. Mastering their advanced techniques will greatly enhance development efficiency and code quality. With the various methods outlined above, developers can handle complex asynchronous scenarios more confidently and write more readable, elegant, and robust code.
If you have worked at all with React hooks before then you have used the useEffect hook extensively. You may not know, though, that there is a second type of useEffect hook called useLayoutEffect. In this article I will be explaining the useLayoutEffect hook and comparing it to useEffect. If you are not already familiar with useEffect check out my full article on it here.
The Biggest Difference
Everything about these two hooks is nearly identical. The syntax for them is exactly the same and they are both used to run side effects when things change in a component. The only real difference is when the code inside the hook is actually run.
In useEffect the code in the hook is run asynchronously after React renders the component. This means the code for this hook can run after the DOM is painted to the screen.
The useLayoutEffect hook runs synchronously directly after React calculates the DOM changes but before it paints those changes to the screen. This means that useLayoutEffect code will delay the painting of a component since it runs synchronously before painting, while useEffect is asynchronous and will not delay the paint.
Why Use useLayoutEffect?
So if useLayoutEffect will delay the painting of a component why would we want to use it. The biggest reason for using useLayoutEffect is when the code being run directly modifies the DOM in a way that is observable to the user.
For example, if I needed to change the background color of a DOM element as a side effect it would be best to use useLayoutEffect since we are directly modifying the DOM and the changes are observable to the user. If we were to use useEffect we could run into an issue where the DOM is painted before the useEffect code is run. This would cause the DOM element to be the wrong color at first and then change to the right color due to the useEffect code.
You Probably Don’t Need useLayoutEffect
As you can see from the previous example, use cases for useLayoutEffect are pretty niche. In general it is best to always use useEffect and only switch to useLayoutEffect when you actually run into an issue with useEffect causing flickers in your DOM or incorrect results.
Conclusion
useLayoutEffect is a very useful hook for specific situations, but in most cases you will be perfectly fine using useEffect. Also, since useEffect does not block painting it is the better option to use if it works properly.
Next.js is an amazing framework that makes writing complex server rendered React apps much easier, but there is one huge problem. Next.js’s caching mechanism is extremely complicated and can easily lead to bugs in your code that are difficult to debug and fix.
If you don’t understand how Next.js’s caching mechanism works it feels like you are constantly fighting Next.js instead of reaping the amazing benefits of Next.js’s powerful caching. That is why in this article I am going to break down exactly how every part of Next.js’s cache works so you can stop fighting it and finally take advantage of its incredible performance gains.
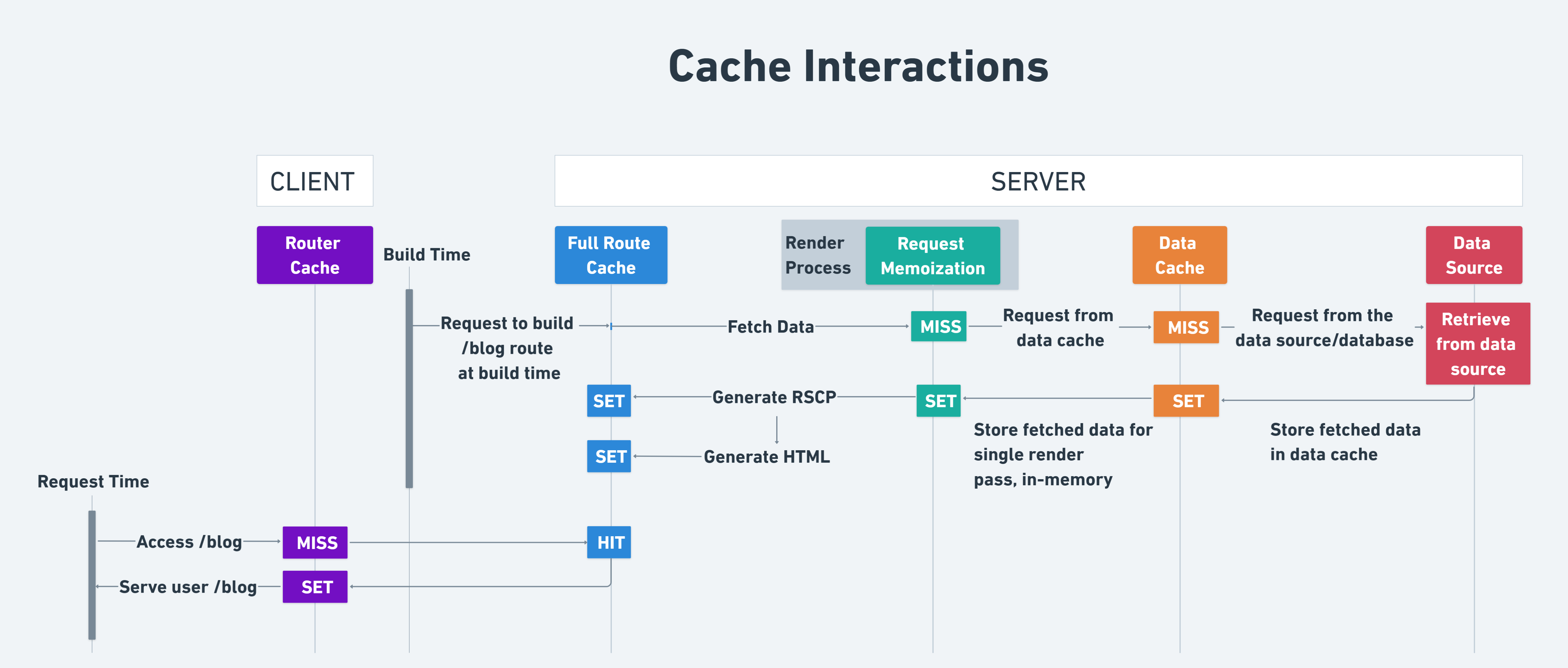
Before we get started, here is an image of how all the caches in Next.js interact with one another. I know this is overwhelming, but by the end of this article you will understand exactly what each step in this process does and how they all interact.
In the image above, you probably noticed the term “Build Time” and “Request Time”. To make sure this does not cause any confusion throughout the article, let me explain them before we move forward.
Build time refers to when an aplication is built and deployed. Anything that is cached during this process (mostly static content) will be part of the build time cache. The build time cache is only updated when the application is rebuilt and redeployed.
Request time refers to when a user requests a page. Typically, data cached at request time is dynamic as we want to fetch it directly from the data source when the user makes requests.
Next.js Caching Mechanisms
Understanding Next.js’s caching can seem daunting at first. This is because it is composed of four distinct caching mechanisms which each operating at different stages of your application and interacting in ways that can initially appear complex.
Here are the four caching mechanisms in Next.js:
Request Memoization
Data Cache
Full Route Cache
Router Cache
For each of the above, I will delve into their specific roles, where they’re stored, their duration, and how you can effectively manage them, including ways to invalidate the cache and opt out. By the end of this exploration, you’ll have a solid grasp of how these mechanisms work together to optimize Next.js’s performance.
Request Memoization
One common problem in React is when you need to display the same information in multiple places on the same page. The easiest option is to just fetch the data in both places that it is needed, but this is not ideal since you are now making two requests to your server to get the same data. This is where Request Memoization comes in.
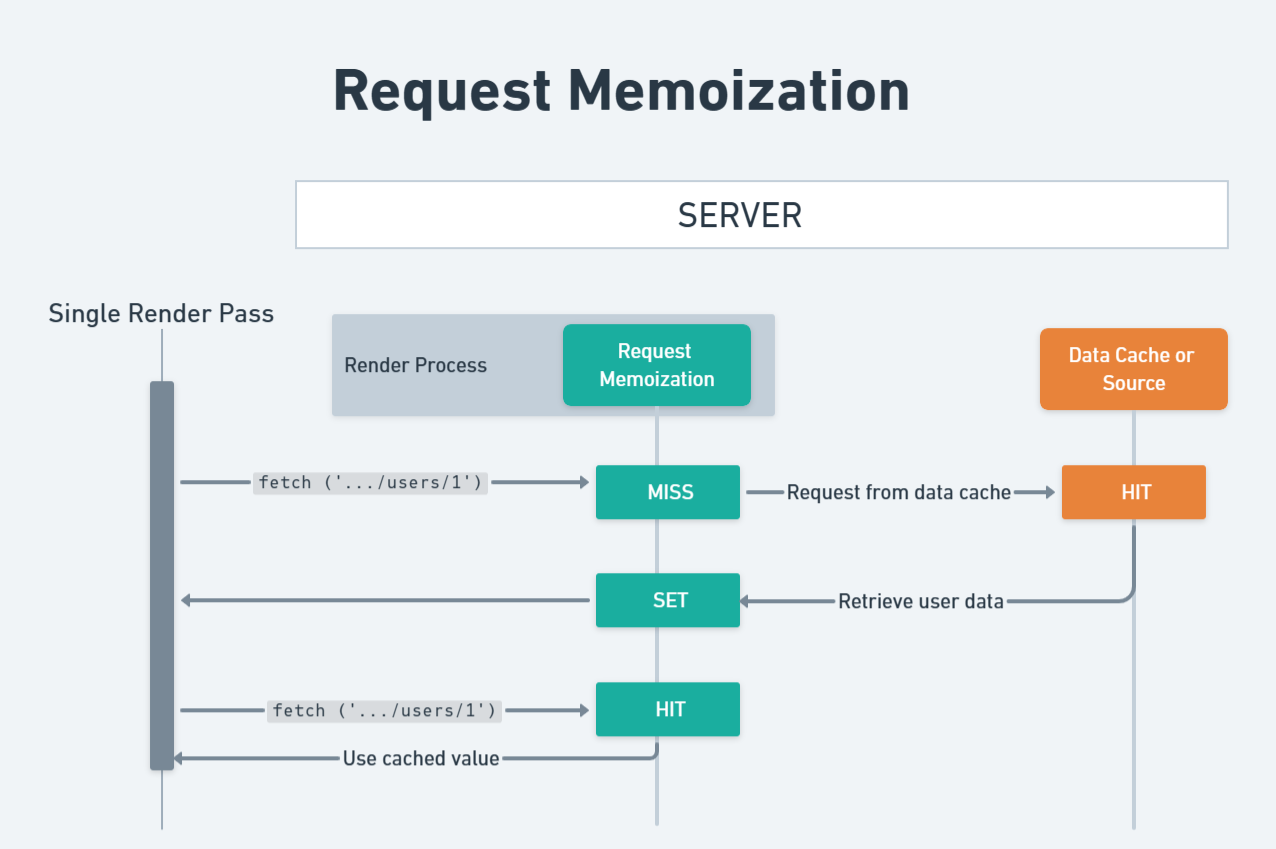
Request Memoization is a React feature that actually caches every fetch request you make in a server component during the render cycle (which basically just refers to the process of rendering all the components on a page). This means that if you make a fetch request in one component and then make the same fetch request in another component, the second fetch request will not actually make a request to the server. Instead, it will use the cached value from the first fetch request.
exportdefaultasyncfunctionfetchUserData(userId) {// The `fetch` function is automatically cached by Next.jsconst res =awaitfetch(`https://api.example.com/users/${userId}`);return res.json();}exportdefaultasyncfunctionPage({ params }) {const user =awaitfetchUserData(params.id);return ( <> <h1>{user.name}</h1> <UserDetailsid={params.id} /> </> );}asyncfunctionUserDetails({ id }) {const user =awaitfetchUserData(id);return <p>{user.name}</p>;}
In the code above, we have two components: Page and UserDetails. The first call to the fetchUserData() function in Page makes a fetch request just like normal, but the return value of that fetch request is stored in the Request Memoization cache. The second time fetchUserData is called by the UserDetails component, does not actually make a new fetch request. Instead, it uses the memoized value from the first time this fetch request was made. This small optimization drastically increases the performance of your application by reducing the number of requests made to your server and it also makes your components easier to write since you don’t need to worry about optimizing your fetch requests.
It is important to know that this cache is stored entirely on the server which means it will only cache fetch requests made from your server components. Also, this cache is completely cleared at the start of each request which means it is only valid for the duration of a single render cycle. This is not an issue, though, as the entire purpose of this cache is to reduce duplicate fetch requests within a single render cycle.
Lastly, it is important to note that this cache will only cache fetch requests made with the GET method. A fetch request must also have the exact same parameters (URL and options) passed to it in order to be memoized.
Caching Non-fetch Requests
By default React only caches fetch requests, but there are times when you might want to cache other types of requests such as database requests. To do this, we can use React’s cache function. All you need to do is pass the function you want to cache to cache and it will return a memoized version of that function.
import { cache } from"react";import { queryDatabase } from"./databaseClient";exportconst fetchUserData =cache((userId) => {// Direct database queryreturnqueryDatabase("SELECT * FROM users WHERE id = ?", [userId]);});
In this code above, the first time fetchUserData() is called, it queries the database directly, as there is no cached result yet. But the next time this function is called with the same userId, the data is retrieved from the cache. Just like with fetch, this memoization is valid only for the duration of a single render pass and works identical to the fetch memoization.
Revalidation
Revalidation is the process of clearing out a cache and updating it with new data. This is important to do since if you never update a cache it will eventually become stale and out of date. Luckily, we don’t have to worry about this with Request Memoization since this cache is only valid for the duration of a single request we never have to revalidate.
Opting out
To opt out of this cache, we can pass in an AbortControllersignal as a parameter to the fetch request.
asyncfunctionfetchUserData(userId) {const { signal } =newAbortController();const res =awaitfetch(`https://api.example.com/users/${userId}`, { signal, });return res.json();}
Doing this will tell React not to cache this fetch request in the Request Memoization cache, but I would not recommend doing this unless you have a very good reason to as this cache is very useful and can drastically improve the performance of your application.
The diagram below provides a visual summary of how Request Memoization works.
Request Memoization is technically a React feature, not exclusive to Next.js. I included it as part of the Next.js caching mechanisms, though, since it is necessary to understand in order to comprehend the full Next.js caching process.
Data Cache
Request Memoization is great for making your app more performant by preventing duplicate fetch request, but when it comes to caching data across requests/users it is useless. This is where the data cache comes in. It is the last cache that is hit by Next.js before it actually fetches your data from an API or database and is persistent across multiple requests/users.
Imagine we have a simple page that queries an API to get guide data on a specific city.
exportdefaultasyncfunctionPage({ params }) {const city = params.city;const res =awaitfetch(`https://api.globetrotter.com/guides/${city}`);const guideData =await res.json();return ( <div> <h1>{guideData.title}</h1> <p>{guideData.content}</p>{/* Render the guide data */} </div> );}
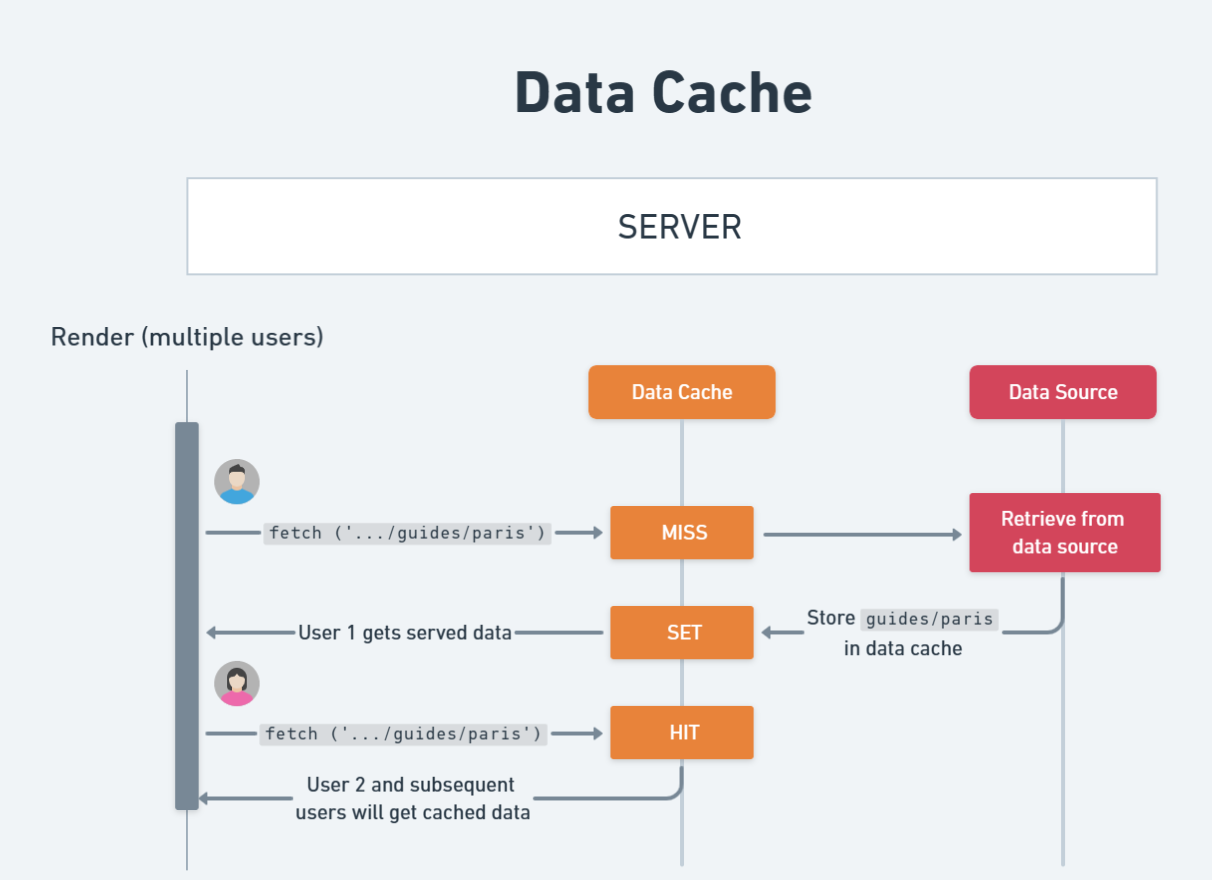
This guide data really doesn’t change often at all so it doesn’t actually make sense to fetch this data fresh everytime someone needs it. Instead we should cache that data across all requests so it will load instantly for future users. Normally, this would be a pain to implement, but luckily Next.js does this automatically for us with the Data Cache.
By default every fetch request in your server components will be cached in the Data Cache (which is stored on the server) and will be used for all future requests. This means that if you have 100 users all requesting the same data, Next.js will only make one fetch request to your API and then use that cached data for all 100 users. This is a huge performance boost.
Duration
The Data Cache is different than the Request Memoization cache in that data from this cache is never cleared unless you specifically tell Next.js to do so. This data is even persisted across deployments which means that if you deploy a new version of your application, the Data Cache will not be cleared.
Revalidation
Since the Data Cache is never cleared by Next.js we need a way to opt into revalidation which is just the process of removing data from the cache. In Next.js there are two different ways to do this: time-based revalidation and on-demand revalidation.
Time-based Revalidation
The easiest way to revalidate the Data Cache is to just automatically clear the cache after a set period of time. This can be done in two ways.
const res =fetch(`https://api.globetrotter.com/guides/${city}`, { next: { revalidate:3600 },});
The first way is to pass the next.revalidate option to your fetch request. This will tell Next.js how many seconds to keep your data in the cache before it is considered stale. In the example above, we are telling Next.js to revalidate the cache every hour.
The other way to set a revalidation time is to use the revalidate segment config option.
exportconst revalidate =3600;exportdefaultasyncfunctionPage({ params }) {const city = params.city;const res =awaitfetch(`https://api.globetrotter.com/guides/${city}`);const guideData =await res.json();return ( <div> <h1>{guideData.title}</h1> <p>{guideData.content}</p>{/* Render the guide data */} </div> );}
Doing this will make all fetch requests for this page revalidate every hour unless they have their own more specific revalidation time set.
The one important thing to understand with time based revalidation is how it handles stale data.
The first time a fetch request is made it will get the data and then store it in the cache. Each new fetch request that occurs within the 1 hour revalidation time we set will use that cached data and make no more fetch requests. Then after 1 hour, the first fetch request that is made will still return the cached data, but it will also execute the fetch request to get the newly updated data and store that in the cache. This means that each new fetch request after this one will use the newly cached data. This pattern is called stale-while-revalidate and is the behavior that Next.js uses.
On-demand Revalidation
If your data is not updated on a regular schedule, you can use on-demand revalidation to revalidate the cache only when new data is available. This is useful when you want to invalidate the cache and fetch new data only when a new article is published or a specific event occurs.
This can be done one of two ways.
import { revalidatePath } from"next/cache";exportasyncfunctionpublishArticle({ city }) {createArticle(city);revalidatePath(`/guides/${city}`);}
The revalidatePath function takes a string path and will clear the cache of all fetch request on that route.
If you want to be more specific in the exact fetch requests to revalidate, you can use revalidateTag function.
const res =fetch(`https://api.globetrotter.com/guides/${city}`, { next: { tags: ["city-guides"] },});
Here, we’re adding the city-guides tag to our fetch request so we can target it with revalidateTag.
import { revalidateTag } from"next/cache";exportasyncfunctionpublishArticle({ city }) {createArticle(city);revalidateTag("city-guides");}
By calling revalidateTag with a string it will clear the cache of all fetch request with that tag.
Opting out
Opting out of the data cache can be done in multiple ways.
no-store
const res =fetch(`https://api.globetrotter.com/guides/${city}`, { cache:"no-store",});
By passing cache: "no-store" to your fetch request, you are telling Next.js to not cache this request in the Data Cache. This is useful when you have data that is constantly changing and you want to fetch it fresh every time.
You can also call the noStore function to opt out of the Data Cache for everything within the scope of that function.
import { unstable_noStoreas noStore } from"next/cache";functiongetGuide() {noStore();const res =fetch(`https://api.globetrotter.com/guides/${city}`);}
Currently, this is an experimental feature which is why it is prefixed with unstable_, but it is the preferred method of opting out of the Data Cache going forward in Next.js.
This is a really great way to opt out of caching on a per component or per function basis since all other opt out methods will opt out of the Data Cache for the entire page.
export const dynamic = 'force-dynamic'
If we want to change the caching behavior for an entire page and not just a specific fetch request, we can add this segment config option to the top level of our file. This will force the page to be dynamic and opt out of the Data Cache entirely.
exportconst dynamic ="force-dynamic";
export const revalidate = 0
Another way to opt the entire page out of the data cache is to use the revalidate segment config option with a value of 0
exportconst revalidate =0;
This line is pretty much the page-level equivalent of cache: "no-store". It applies to all requests on the page, ensuring nothing gets cached.
Caching Non-fetch Requests
So far, we have only seen how to cache fetch requests with the Data Cache, but we can do much more than that.
If we go back to our previous example of city guides, we might want to pull data directly from our database. For this, we can use the cache function that’s provided by Next.js. This is similar to the React cache function, except it applies to the Data Cache instead of Request Memoization.
Currently, this is an experimental feature which is why it is prefixed with unstable_, but it is the only way to cache non-fetch requests in the Data Cache.
The code above is short, but it can be confusing if this is the first time you are seeing the cache function.
The cache function takes three parameters (but only two are required). The first parameter is the function you want to cache. In our case it is the getGuides function. The second parameter is the key for the cache. In order for Next.js to know which cache is which it needs a key to identify them. This key is an array of strings that must be unique for each unique cache you have. If two cache functions have the same key array passed to them they will be considered the same exact request and stored in the same cache (similar to a fetch request with the same URL and params).
The third parameter is an optional options parameter where you can define things like a revalidation time and tags.
In our particular code we are caching the results of our getGuides function and storing them in the cache with the key ["guides-cache-key"]. This means that if we call getCachedGuides with the same city twice, the second time it will use the cached data instead of calling getGuides again.
Below is a diagram that walks you through how the Data Cache operates, step by step.
Full Route Cache
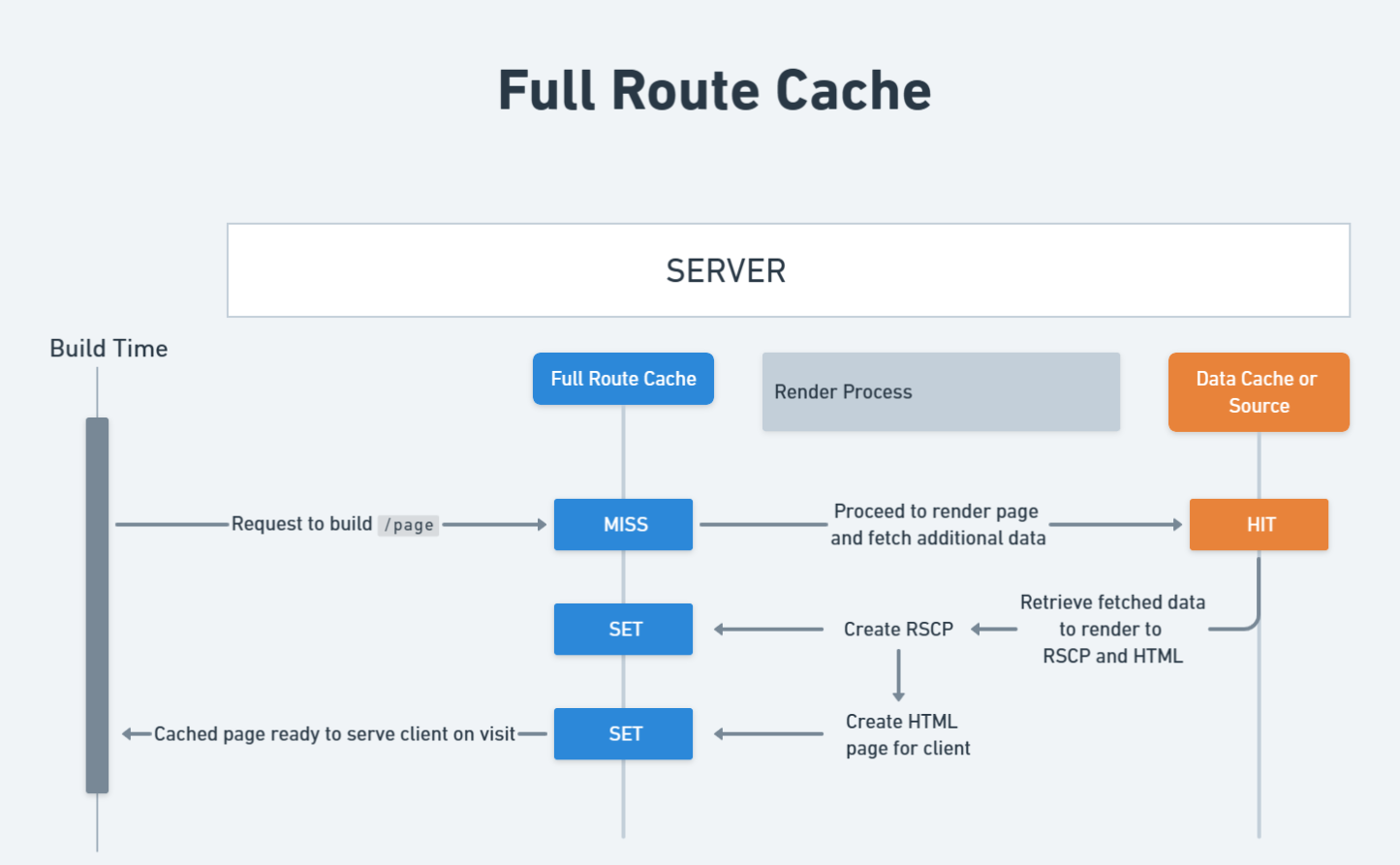
The third type of cache is the Full Route Cache, and this one is a bit easier to understand since is much less configurable than the Data Cache. The main reason this cache is useful is because it lets Next.js cache static pages at build time instead of having to build those static pages for each request.
In Next.js, the pages we render to our clients consist of HTML and something called the React Server Component Payload (RSCP). The payload contains instructions for how the client components should work together with the rendered server components to render the page. The Full Route Cache stores the HTML and RSCP for static pages at build time.
Now that we know what it stores, let’s take a look at an example.
In the code I have above, Page will be cached at build time because it does not contain any dynamic data. More specifically, its HTML and RSCP will be stored in the Full Router Cache so that it is served faster when a user requests access. The only way this HTML/RSCP will be updated is if we redeploy our application or manually invalidate the data cache that this page depends on.
I know you may think that since we are doing a fetch request that we have dynamic data, but this fetch request is cached by Next.js in the Data Cache so this page is actually considered static. Dynamic data is data that changes on every single request to a page, such as a dynamic URL parameter, cookies, headers, search params, etc.
Similarly to the Data Cache the Full Route Cache is stored on the server and persists across different requests and users, but unlike the Data Cache, this cache is cleared every time you redeploy your application.
Opting out
Opting out of the Full Route Cache can be done in two ways.
The first way is to opt out of the Data Cache. If the data you are fetching for the page is not cached in the Data Cache then the Full Route Cache will not be used.
The second way is to use dynamic data in your page. Dynamic data includes things such as the headers, cookies, or searchParams dynamic functions, and dynamic URL parameters such as id in /blog/[id].
The diagram below demonstrates the step-by-step process of how Full Route Cache works.
This cache only works with your production builds since in development all pages are rendered dynamically, thus, they are never stored in this cache.
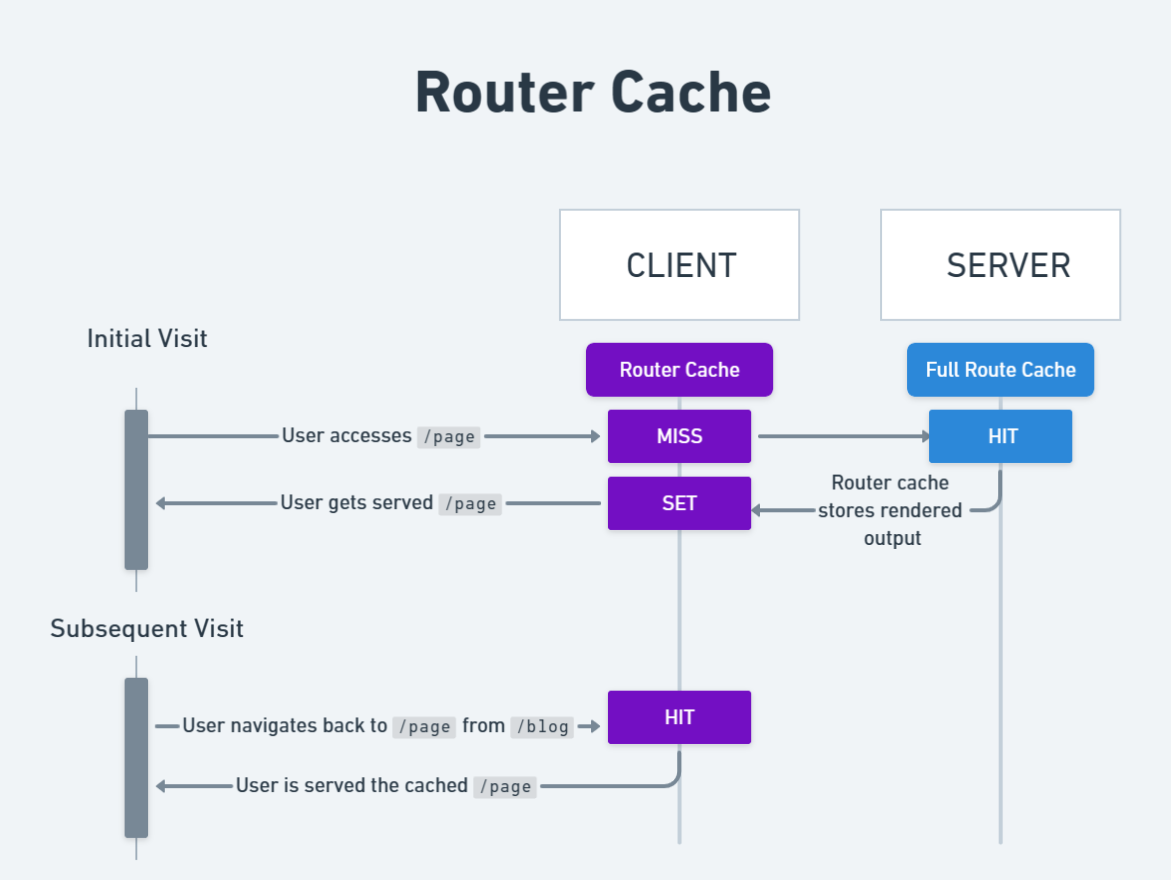
Router Cache
This last cache is a bit unique in that it is the only cache that is stored on the client instead of on the server. It can also be the source of many bugs if not understood properly. This is because it caches routes that a user visits so when they come back to those routes it uses the cached version and never actually makes a request to the server While this approach is an advantage when it comes to page loading speeds, it can also be quite frustrating. Let’s take a look below at why.
In the code I have above, when the user navigates to this page, its HTML/RSCP gets stored in the Router Cache. Similarly, when they navigate to any of the /blog/${post.slug} routes, that HTML/RSCP also gets cached. This means if the user navigates back to a page they have already been to it will pull that HTML/RSCP from the Router Cache instead of making a request to the server.
Duration
The router cache is a bit unique in that the duration it is stored for depends on the type of route. For static routes, the cache is stored for 5 minutes, but for dynamic routes, the cache is only stored for 30 seconds. This means that if a user navigates to a static route and then comes back to it within 5 minutes, it will use the cached version. But if they come back to it after 5 minutes, it will make a request to the server to get the new HTML/RSCP. The same thing applies to dynamic routes, except the cache is only stored for 30 seconds instead of 5 minutes.
This cache is also only stored for the user’s current session. This means that if the user closes the tab or refreshes the page, the cache will be cleared.
You can also manually revalidate this cache by clearing the data cache from a server action using revalidatePath/revalidateTag. You can also call the router.refresh function which you get from the useRouter hook on the client. This will force the client to refetch the page you are currently on.
Revalidation
We already discussed two ways of revalidation in the previous section but there are plenty of other ways to do it.
We can revalidate the Router Cache on demand similar to how we did it for the Data Cache. This means that revalidating Data Cache using revalidatePath or revalidateTag also revalidates the Router Cache.
Opting out
There is no way to opt out of the Router Cache, but considering the plethora of ways to revalidate the cache it is not a big deal.
Here is an image that provides a visual summary of how the Router Cache works.
Conclusion
Having multiple caches like this can be difficult to wrap your head around, but hopefully this article was able to open your eyes to how these caches work and how they interact with one another. While the official documentation mentions that knowledge of caching is not necessary to be productive with Next.js, I think it helps a lot to understand its behavior so that you can configure the settings that work best for your particular app.
React 18 recently had its official non-beta release and with it came multiple new React hooks. Of those hooks, the one I am most excited for is the useTransition hook. This hook helps increase the performance of your applications, increase the responsiveness of your application to users, and overall just make your application better. This article is all about how this new hook works and is also full of multiple interactive examples so you can truly see and feel the difference in using this hook.
Why Do You Need useTransition?
Before we can talk about what this hook does and how to use it we first need to understand a few concepts about how state works in React in order to understand the use case for this hook.
This is a very simple component with two state variables that both get updated at the same time when we change the value in our input field. If you are unfamiliar with the useState hook then you should check out my complete useState hook article before reading further.
React is smart enough to see that these state updates happen at the same time so it will group them together and perform both state updates before rendering the component again. This is really nice since it only renders the component once after all the state changes instead of twice (once after each state change).
This works really well in most cases but it can lead to performance problems.
In this example we are now setting a list variable based on the value we type in our input. Normally this is not something you would want to do since storing derived state in React is bad. If you want to learn why, I explain this in depth in my article on derived state.
Our list is incredibly long so looping through the entire list, filtering each item, and rendering them all to the screen is quite time consuming and especially on older devices will be very slow to process. This is a problem since this list state update happens at the same time as the name state update so the component won’t rerender with the new state values for either piece of state until both finish processing which means the input field will feel very slow. Below is an example of what this would look like.
Instead of rendering out thousands of items to the screen, I am instead emulating the slowness artificially and only rendering a few items to the screen so as to not overwhelm your computer. Also, the items being rendered are just exact copies of whatever you type in to the input field and you can only enter one character at a time into the input field or it will not work as expected.
Item: a
Item: a
Item: a
Item: a
Item: a
As you can see in this example when you try to type into the input box it is really slow and takes about a second to update the input box. This is because rendering and processing the list takes so long. This is where useTransition comes in.
useTransition Explained
The useTransition hook allows us to specify some state updates as not as important. These state updates will be executed in parallel with other state updates, but the rendering of the component will not wait for these less important state updates.
Calling the useTransition hook returns an array with the first value being an isPending variable and the second value being the startTransition function. The isPending variable simply returns true while the code inside the startTransition hook is running. Essentially, this variable is true when the slow state update is running and false when it is finished running. The startTransition function takes a single callback and this callback just contains all the code related to the slow state update including the setting of the state.
In our case we are wrapping setList in our startTransition function which tells React that our setList state update is of low importance. This means that as soon as all of our normal state updates are finished that the component should rerender even if this slow state update is not finished. Also, if a user interacts with your application, such as clicking a button or typing in an input, those interactions will take higher priority than the code in the startTransition function. This ensures that even if you have really slow code running it won’t block your user from interacting with the application.
Here is an example of what our list acts like with the useTransition hook.
Item: a
Item: a
Item: a
Item: a
Item: a
You can see that our input updates immediately when you type, but the actual list itself does not update until later. While the list is updating the text Loading... renders and then once the list finishes loading is renders the list.
Using this hook is quite easy, but this is not something you want to use all the time. You should only use this hook if you are having performance issues with your code and there are no other ways to fix those performance concerns. If you use this hook all the time you will actually make your app less performant since React will not be able to effectively group your state updates and it will also add extra overhead to your application.
Conclusion
The useTransition hook makes working with slow, computationally intense state updates so much easier since now we can tell React to prioritize those updates at a lower level to more important updates which makes your application seem much more performant to users.